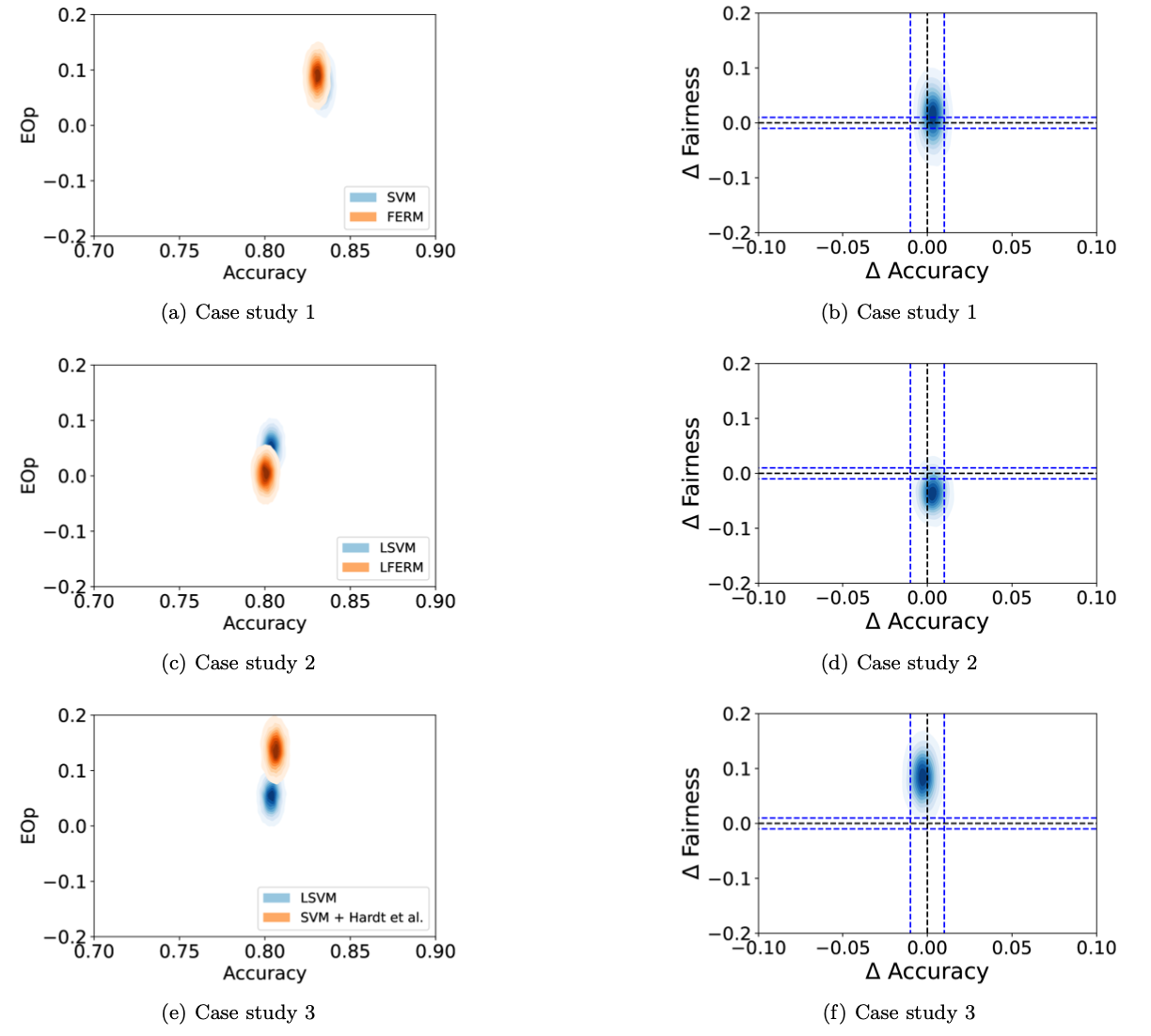
Uncertainty matters: stable conclusions under unstable assessment of fairness results
Recent studies highlight the effectiveness of Bayesian methods in assessing algorithm performance, particularly in fairness and bias evaluation. We present Uncertainty Matters, a multi-objective uncertainty-aware algorithmic comparison framework. In fairness focused scenarios, it models sensitive group confusion matrices using Bayesian updates and facilitates joint comparison of performance (e.g., accuracy) and fairness metrics (e.g., true positive rate parity). Our approach works seamlessly with common evaluation methods like K-fold cross-validation, effectively addressing dependencies among the K posterior metric distributions. The integration of correlated information is carried out through a procedure tailored to the classifier’s complexity. Experiments demonstrate that the insights derived from algorithmic comparisons employing the Uncertainty Matters approach are more informative, reliable, and less influenced by particular data partitions.
View Full-Text. Python code available at GitHub repository
Preserving the fairness guarantees of classifiers in changing environments: a survey
The impact of automated decision-making systems on human lives is growing, emphasizing the need for these systems to be not only accurate but also fair. The field of algorithmic fairness has expanded significantly in the past decade, with most approaches assuming that training and testing data are drawn independently and identically from the same distribution. However, in practice, differences between the training and deployment environments exist, compromising both the performance and fairness of the decision-making algorithms in real-world scenarios. A new area of research has emerged to address how to maintain fairness guarantees in classification tasks when the data generation processes differ between the source (training) and target (testing) domains. The objective of this survey is to offer a comprehensive examination of fair classification under distribution shift by presenting a taxonomy of current approaches. The latter is formulated based on the available information from the target domain, distinguishing between adaptive methods, which adapt to the target environment based on available information, and robust methods, which make minimal assumptions about the target environment. Additionally, this study emphasizes alternative benchmarking methods, investigates the interconnection with related research fields, and identifies potential avenues for future research.
View Full-Text